[Collection Framework] Map, Set, List 중 Map에 대해서 알아보자

자바는 최상위에 Collection Framework를 가진다. 크게 Collection Framework하위에 Map과 Collection인터페이스로 나뉜다. 컬렉션 프레임워크는 컬렉션을 표현하고 조작하기 위한 통합 아키텍처로, 컬렉션이 구현 세부 사항과 독립적으로 조작될 수 있도록 합니다.
이러한 컬렉션 프레임워크 덕분에 데이터 구조와 알고리즘을 제공하여 직접 작성할 필요가 없는 장점이 있습니다. 또한 컬렉션 인터페이스를 구현함으로써 List, Set, Queue에서는 동일한 api를 사용합니다. ex) add(), clear()...
- Map
- Key와 Value의 형태로 이루어진 데이터 집합
- 순서를 보장하지 않는다.
- Key는 중복이 허용되지 않고, Value는 중복을 허용한다.
- 내부적으로 링크드리스트, 배열(버킷)로 구현되어있다.
- Collection 하위 인터페이스
- List
- 순서가 있는 데이터 집합
- 데이터를 중복해서 포함시킬 수 있다.
- Set
- 데이터의 중복을 허용하지 않는다.
- 순서를 보장하지 않는다.
- 내부적으로 HashMap으로 구현되어있다.
- List
Concurrent Collections
동시성 문제를 해결하기 위해 지원해준다.
BlockingQueue,TransferQueue, BlockingDeque,ConcurrentMap 등 다양한 인터페이스가 있다. 그리고 LinkedBlockingQueue, ArrayBlockingQueue, ConcurrentHashMap등 다양한 구현 클래스가 있다.
이렇게 설계한 목표는 최대한 작은 core 인터페이스만 만드려고 했다고 합니다. 추후에 추가될 기능의 교체가 아닌 증설을 목적으로 개념적 가중치가 있는 API를 만드려고 CollectionFramework를 디자인했다고 합니다.
Map
Map은 key, value 쌍으로 이루어진 대표적인 자료구조입니다. 자바에서 사용하는 Map은 내부적으로 배열로 이루어져있습니다. key값이 들어오면 이 값을 해싱을 합니다. 해싱한 값을 배열의 인덱스로 하고 value를 해당 배열(버킷)의 인덱스 위치에 저장합니다.
그런데 해시값을 이용하기때문에 해시 충돌이 발생할 수 있습니다. 해시 충돌을 해결하는 방법으로는 크게 Open Addressing과 Separate Chaining 방식이 있습니다. 이중 자바의 Map은 Separate Chaining 을 사용합니다.
OpenAddressing은 해시 충돌이 발생하면 다른 버킷 위치에 해당 value를 넣어서 해결합니다. 이러한 방법은 연속된 공간에 데이터를 저장하기 때문에 Separate Chaining에 비하여 캐시 효율이 높습니다. 따라서 데이터 개수가 충분히 적다면 Open Addressing이 Separate Chaining보다 더 성능이 좋다.
하지만 Java의 HashMap이 SeparateChaining 을 사용하는 이유는 remove에 관련이 있다. OpenAddressing은 key를 삭제한 후 다시 정렬해야 하는 추가 작업이 필요합니다. 따라서 자바의 Map은 Separate Chaining 을 사용합니다.
이때 자바의 HashMap은 특징이 있습니다.
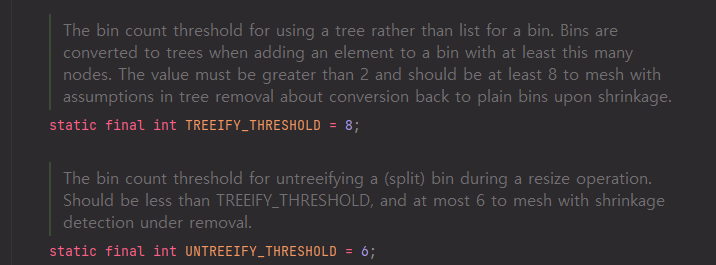
해시 충돌이 발생해서 링크드 리스트가 8개 이상이 되는 순간 링크드 리스트가 Tree형태로 변환이 됩니다. 이때 사용되는 트리는 RBTree라고 합니다. RedBlackTree는 최악의 경우도 O(logn)으로 유지할 수 있는 트리입니다. 따라서 충돌 데이터가 너무 많다면 트리 형태로 변환해서 탐색 속도를 높인 것입니다. 마찬가지로 6개가 되면 다시 리스트 형태로 변환됩니다. 2의 차이를 둔 이유는 -,+반복으로 매번 자료구조가 변하면 비용이 들기 때문에 차이를 2로 두었다고 합니다.
8을 기준으로 한 이유는 트리는 링크드 리스트보다 메모리 사용량이 많고, 데이터의 개수가 적을 때 트리와 링크드 리스트의 Worst Case 수행 시간 차이 비교는 의미가 없기 때문에 8로 설정한것 같습니다.
버킷의 확장
해시 충돌을 Separate Chaining으로 해결해준다면 버킷은 언제 확장할까요?
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
해시 버킷은 기본값이 16입니다. 따라서 해당 버킷의 3/4(0.75)가 차게 된다면 2배로 사이즈를 늘리는 작업을 합니다. 이렇게 되면 체이닝도 다시 설정되어야 하니 성능이 안 좋아질 수 있습니다. 따라서 어느 정도 크기가 예상이 된다면 미리 버킷의 크기를 잡아주는 것도 방법입니다.
HashMap은 보조 해시 함수(Additional Hash Function)를 사용하기 때문에 보조 해시 함수를 사용하지 않는 HashTable에 비하여 해시 충돌(hash collision)이 덜 발생할 수 있어 상대적으로 성능상 이점이 있습니다.
보조 해시 함수는 %(모듈러)연산을 했을 때, 고르지 않게 나오는 문제를 해결해준다. 예를 들어 해시 버킷이 2배씩 확장하므로 2의 지수승으로 확장되므로 %연산으로 적극 2^30 범위를 확보하지 못한다. 2^a로 모듈러하면 a비트만 활용하기 때문이다. (사실 31과 같은 소수를 활용하면 더 다양한 비트를 활용할 수 있을 것이다.)
따라서 보조 해시 함수를 통해서 해결한다.

xor연산을 통해서 해결을 한다. java docs에 설명이 있다.
There is a tradeoff between speed, utility, and quality of bit-spreading. Because many common sets of hashes are already reasonably distributed (so don't benefit from spreading), and because we use trees to handle large sets of collisions in bins, we just XOR some shifted bits in the cheapest possible way to reduce systematic lossage, as well as to incorporate impact of the highest bits that would otherwise never be used in index calculations because of table bounds.
대부분의 해시의 집합들은 이미 합리적으로 분배가 되었다.(따라서 비트를 조금만 사용한다고 해도 해시 충돌이 발생할 확률이 줄었다.) 게다가 해시충돌을 tree로 다루기 때문이다. 따라서 해싱한 값에 대해서 xor 같은 비트 연산을 통해서 빠르게 연산하여 수행 속도를 상승시키는 목적으로 보조 해시함수를 사용한다고 합니다.
Map
이러한 Map도 5가지로 구현됩니다. HashMap, TreeMap, LinkedHashMap, ConcurrentHashMap, HashTable
HashMap
- synchronized가 안 걸려있어서 thread-safe하지 않습니다.
- null을 허용합니다.
TreeMap
- synchronized가 안 걸려있어서 thread-safe하지 않습니다.
- default로 key값을 기준으로 오름차순으로 정렬이됩니다.(Comparator를 구현하여 정렬방법을 설정할 수 있습니다.)
- null을 허용하지 않습니다.
- red-black tree로 구현되어 있습니다.
LinkedHashMap
- synchronized가 안 걸려있어서 thread-safe하지 않습니다.
- 입력 순서가 보장이 됩니다.
- null을 허용합니다.
ConcurrentHashMap
- put에서 내부적으로 synchronized가 걸려있어서 동시성을 보장해줍니다. 같은 버킷에 접근하는 로직에만 synchronized를 걸어서 해결해줍니다.
- null을 허용하지 않습니다.
HashTable
- synchronized가 get, put모두에 걸려있어서 성능상 좋지 않습니다.
- null을 허용하지 않습니다.
Set
속도는 HashSet = LinkedHashSet > TreeSet로 HashSet과 LinkedHashSet은 비슷합니다. 하지만 TreeSet은 매번 정렬해야 하므로 느립니다.
HashSet
- 저장 순서를 유지하지 않는 데이터의 집합
- Null 저장 가능
- 해시 알고리즘을 사용하여 검색속도가 매우 빠르다.
- 내부적으로 HashMap으로 구현되어 있습니다.
LinkedHashSet
- 저장 순서를 유지하는 HashSet
- 내부적으로 LinkedHashMap으로 구현되어 있습니다.
TreeSet
- 데이터가 정렬된 상태로 저장되는 이진 탐색 트리의 형태로 요소를 저장한다.
- Null 저장 불가능
- 레드 블랙 트리(균형 이진 탐색 트리) 로 구현되어 있다.
- Compartor 구현으로 정렬 방법을 지정할 수 있다.
- 내부적으로 TreeMap으로 구현되어 있습니다.
List
- ArrayList
- 내부적으로 배열을 사용하는 자료구조로 메모리가 연속적으로 배치된다.
- 배열과 달리 메모리 할당이 동적이다.
- 배열은 Compile time에 할당되어 힙에 저장되는 정적 메모리 할당
- 리스트는 새로운 Node가 추가되고 runtime에 할당되어 힙에 저장되는 동적 메모리 할당
- 데이터 삽입, 삭제 시 해당 데이터 이후 모든 데이터가 복사되므로 빈번한 삭제, 삽입이 일어나는 경우에는 부적합하다.
- 재할당 시 크기의 절반씩 증가한다.
- LinkedList
- 양방향 포인터 구조로 각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조
- 데이터의 삽입, 삭제 시 해당 노드의 주소지만 바꾸면 되므로 삽입, 삭제가 빈번한 데이터에 적합하다.
- 메모리가 불연속적이다.
- 데이터 검색 시 처음부터 순회하므로 검색에는 부적합하다.
- 스택, 큐, 양방향 큐를 만들기 위한 용도로 사용한다.
- 양옆의 정보만을 갖고 있기 때문에 순차적으로 검색을 진행하여 검색 속도가 느리다.
Reference
https://docs.oracle.com/javase/8/docs/technotes/guides/collections/index.html