캐시(1) Redis란?

Redis(Remote Dictionary Server)란?
“key-value” 구조로 데이터를 저장하고 관리하기 위한 비 관계형 데이터베이스로 모든 데이터를 메모리에서 처리하는 메모리 기반 DB이다. 메모리를 통해 사용하기 때문에 일반적인 DB보다 빠른 성능을 보여준다.
레디스는 싱글 스레드로 동작한다.
캐시
매번 디비에 접근해서 디스크를 일고 쓰는 것은 비용이 크다. 따라서 데이터를 메모리에 두어 디스크에 접근을 최소화하는 방법이다.
어떤 정보를 캐시할까
- 잘 안 바뀌는데, 자주 읽어오는 경우 ex) 로그인 정보
- key마다 태그를 달아서 어떤 데이터가 많이 생성되는지 확인한다.
캐시 vs 버퍼
버퍼는 주로 차기를 기다려서 꽉 차면 보내주고, cache는 미리 계산하고 가져온다.
버퍼는 쓰기를 위해서 주로 저장한다. 느린 것을 덜 느리게 사용하기 위해서 그리고 캐시는 읽기에서 더 빠른 성능을 위해서이다. 빠른 것을 더 빠르게 하기 위해서
로컬 캐시(EHCACHE) vs In memory DB
- 속도는 당연히 로컬 캐시가 빠르다. ex) Integer 125, 캐시가 없어지면 안 되기 때문에 또 문제다.
- 동기화에 문제가 있다. 단순히 서버가 2개로만 늘어나도 하나의 서버에서 데이터가 바뀌면 다른 서버에 통보해줘야 한다. 이때, 동기화의 문제가 발생할 수 있다. 맞추기도 어렵고 똑같은 정보를 모든 서버가 같이 들고 있기 때문에 중복이 발생한다.
- 따라서 외부에 인메모리 디비를 두면 동기화에 더 유연하다.
데이터베이스에 저장하면 될 거 같은데 인메모리 디비는 왜 사용할까?
디스크는 초당 천 번 정도 쓰면 메모리에 접근하면 10만 번 정도 가능하다. 디스크는 물리적으로 팬이 헤드가 돌아야 하므로 느리다. 디스크를 쓰는 이유는 영속적으로 저장하기 위해서이다. 대신 메모리에 올리므로 날아갈 수 있다. 따라서 날아가도 괜찮은 것을 저장해야 한다.
날아가면 안 되는 것 - store
날아가도 되는 것 - cache
캐시가 다운될 경우
따라서 캐시가 장애가 나면 모든 트래픽이 디비로 가므로 디비는 항상 캐시를 염두에 두고 디비 크기를 구성해야 한다.
멀티 플렉싱
Redis의 동작 원리를 살펴보면 Redis는 이벤트 루프(Event Loop)와 비슷한 multiplexing을 이용하여 요청을 수행합니다.
즉, 실제 명령에 대한 작업(Task)은 커널 레벨에서 멀티플렉싱(Multiplexing)을 통해 처리하여 동시성을 보장합니다. 쉽게 유저 레벨에서는 싱글 스레드로 동작하지만, 커널 I/O 레벨에서는 4개의 스레드 풀을 이용하는 것입니다.
캐시 구조
Write Through 구조
캐시와 DB에 항상 동시에 데이터를 기록하는 방식입니다. 항상 최신의 데이터가 유지되지만, 쓰기 작업이 많을 경우 캐시와 DB에 매번 통신하는 비용이 발생합니다.
Write Back 구조
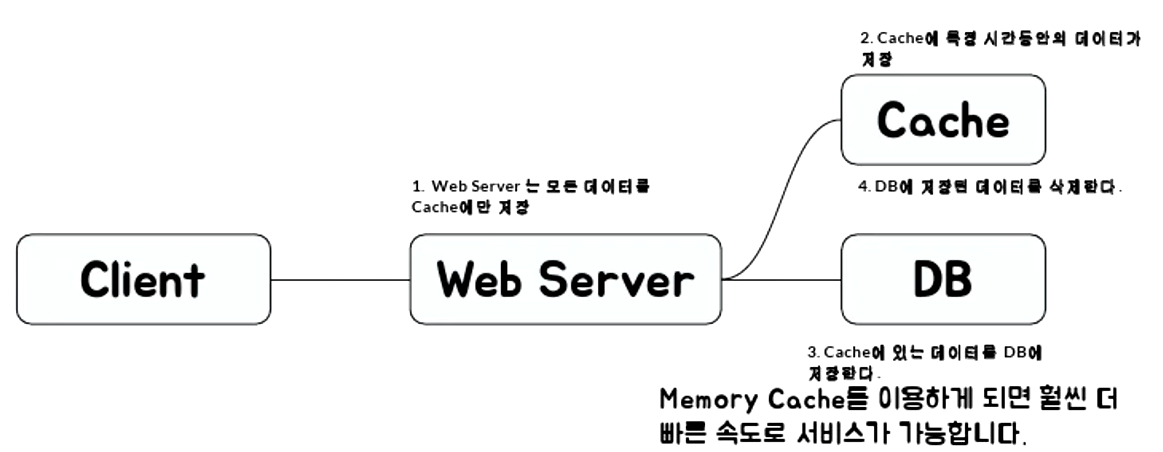
데이터를 캐시에만 기록합니다. 이후에 캐시에 있는 데이터를 DB에 한번에 등록합니다.장점은 쓰기가 많이 일어나도 캐시에만 업데이트 되기 때문에 빠른 처리가 가능합니다. 하지만 캐시 자체는 휘발성 메모리라서 데이터 유실 가능성이 있습니다.
Look Aside 구조

이 방식은 캐시에 데이터가 있는 cache hit 시에는 캐시에서 데이터를 가져오고, 캐시에 데이터가 없는 cache miss 시에는 DB에서 데이터를 가져와 다시 캐시에 저장하고 결과를 반환하는 구조입니다.
cache miss가 일어나도, DB에서 다시 가져올 수 있다. 하지만 캐시에 데이터가 있는 채로 DB 데이터가 변경되었다면, 캐시와 DB 데이터가 다른 불일치 문제가 발생합니다.
TTL존재 이유
그렇기 때문에 Look aside 구조를 적용한다면 데이터 불일치 문제에 대한 해결 전략을 추가해야합니다. 스프링 데이터 레디스 문서에서는 TTL(Time to Live)이라는 기능을 제공합니다. redis 데이터의 만료기간을 설정하여, TTL기간이 지나면 캐시 데이터가 없어지게 됩니다. TTL을 설정함으로써 자연스럽게 캐시 값이 없어지고, 자가진단 관련 데이터 조회 시 DB 데이터를 캐시에 저장하게되면서 최신의 DB 데이터를 캐시에 담을 수 있게 됩니다.
결론적으로 문제 해결을 위해 Look Aside 구조와 TTL을 적용합니다.
동시성 vs 병렬성
- 동시성: 하나의 코어에서 2개의 쓰레드가 번갈아가면서 작업할 때
- 병렬성: 아예 다른 2개의 코어가 각자 일을 할 때,
싱글 스레드인 이유는?
- Context-Switch(문맥교환)가 없어 성능이 더 좋다.
- 교착 상태(데드락)을 고려하지 않아도 된다.
EXPIRE 처리 방법
- 수동 처리: key를 확인할 때, 만료시간을 확인해서 없앤다.
- 자동 처리(default): 만료가 있는 키 20개 정도를 확인한다. → 만료 키를 제거한다 → 25% 정도 제거된다면 다시 이 사이클을 반복한다.
Redis vs Memcached
공통점
- key-value 자료구조를 가진다.
- 만료일을 지정해서 만료일이 지난 데이터를 삭제할 수 있다. (하지만 지원 방법은 다르다)
- MemCached의 경우, LRU(Least Recently Used) 알고리즘만 채택한다.
- Redis는 다양한 알고리즘 채택할 수 있다.
- No Eviction: 기한을 정하지 않는다. 메모리가 부족하면 에러를 발생한다.
- All Keys LRU: LRU에 근거해서 삭제한다.
- Volatile LRU: LRU에 근거하되 만료 시점이 지정된 것들에 한해서 삭제한다.
- All Keys Random: 랜덤하게 키 삭제한다.
- Volatile Random: 랜덤하게 키 삭제하되 만료 시점이 지정된 것들에 한해서 삭제한다.
- Volatile TTL: TTL 값을 기반으로, 만료 시점이 빨리 도래하는 순서대로 삭제한다.
Redis
- 스냅샷을 통해 특정 시점에 데이터를 디스크에 저장하여 영속성을 지원한다.
- collection같은 data structure를 제공해준다.
- Master-Slaves 구조로 만들 수 있다.
- Pub/ Sub Messag을 지원하여 채팅, 실시간 스트리밍에서 사용 가능하다.
- 싱글 스레드이다.
- 트랜잭션을 지원한다.
- MULTI: 트랜잭션 시작
- DISCARD: 트랜잭션 취소
- EXEC: 트랜잭션 커밋
- WATCH: 특정 key의 변경 여부 감시
- UNWATCH: WATCH취소
- 쓰기 성능 증가를 위한 샤딩 지원
Memcached
- 데이터가 메모리에만 저장된다. 데이터는 프로세스가 종료되면 사라진다.
- 문자열만 지원한다.
- 멀티스레드 구조이므로 redis보다 성능이 훨씬 빠르다.
- 키 벨류 꺼내는 get/set 밖에 없다.
===================================
Redis 설정
Lettuce vs Jedis
Spring Data Redis에서 사용할 수 있는 Redis Client 구현체는 크게 Lettuce와 Jedis가 있다. 결론부터 이야기하자면, 이번 프로젝트에서는 Lettuce를 사용했다.
spring-boot-starter-data-redis 을 사용하면 별도의 의존성 설정 없이 Lettuce를 사용할 수 있다. 반면 Jedis는 별도의 설정이 필요하다.
Jedis를 사용하지 않는 이유는 몇 가지 더 있다. 이동욱님의 아래의 포스팅을 읽어보면, Lettuce가 더 높은 성능을 내고, 문서도 더 잘 되어있고, 오픈소스도 더 잘 관리되고 있다고 한다. 이런 여러 이유로 이번 프로젝트에서는 Lettuce를 사용한다.
https://jojoldu.tistory.com/418
Jedis 보다 Lettuce 를 쓰자
Java의 Redis Client는 크게 2가지가 있습니다. Jedis Lettuce 둘 모두 몇천개의 Star를 가질만큼 유명한 오픈소스입니다. 이번 시간에는 둘 중 어떤것을 사용해야할지에 대해 성능 테스트 결과를 공유하
jojoldu.tistory.com
======
Redis Repository vs Redis Template
스프링부트에서 Redis를 사용하는 방법에는 두 가지가 있다. Repository 인터페이스를 정의하는 방법과 Redis Template을 사용하는 방법이다.
Repository

Repository 인터페이스를 정의하는 방법은 Spring Data JPA를 사용하는 것과 비슷하다. Redis는 많은 자료구조를 지원하는데, Repository를 정의하는 방법은 Hash 자료구조로 한정하여 사용할 수 있다. Repository를 사용하면 객체를 Redis의 Hash 자료구조로 직렬화하여 스토리지에 저장할 수 있다.
- 트랜잭션을 지원하지 않는다.
Redis Template
Redis Template은 Redis 서버에 커맨드를 수행하기 위한 고수준의 추상화(high-level abstraction)를 제공한다.
transactional을 지원한다.
메소드명반환 오퍼레이션관련 Redis 자료구조
| opsForValue() | ValueOperations | String |
| opsForList() | ListOperations | List |
| opsForSet() | ListOperations | List |
| opsForList() | SetOperations | Set |
| opsForZSet() | ZSetOperations | Sorted Set |
| opsForHash() | HashOperations | Hash |
적용
Redis를 도입한 이유는 저희 서비스의 인증 방식이 액세스 토큰과 리프레시 토큰을 사용한다. 이때, 액세스 토큰이 만료될 때마다 디비에서 리프레시 토큰을 비교하여 유효하면 재발급해주는데
1. 이처럼 잦은 요청과 응답이 발생하므로 인 메모리 디비인 레디스를 사용하여 성능을 높이기 위해서
2. redis는 만료 기간이 지나면 자동으로 삭제를 해주는 옵션을 줄 수 있다. 따라서 현재 서비스에서 이전에 발급했던 토큰을 디비에 저장해서 탈취당했는지의 여부를 판단한다. 일정 기간이 지나면 토큰이 무효화되기 때문에 디비에서 지워야 하는데 레디스를 사용하지 않으면 스케쥴러를 돌려야 한다. 즉, 비즈니스 로직에만 집중할 수 있지 못한다. 불필요한 코드를 만든다.
Reference
https://www.youtube.com/watch?v=mPB2CZiAkKM&t=3978s
https://www.youtube.com/watch?v=zkbvFOwJFgA&t=3225s