
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 자바
- AOP
- 우아한테크코스
- 트랜잭션
- 세션
- 스프링 부트
- JPA
- 백준
- AWS
- 의존성
- 서블릿
- JUnit5
- 코드리뷰
- mock
- 우테코
- yml
- 프리코스
- 스프링부트
- 우아한세미나
- Level2
- HTTP
- MSA
- CircuitBreaker
- 미션
- REDIS
- Spring Batch
- Docker
- 프로그래머스
- Paging
- 레벨2
- Today
- Total
늘
[우아한 세미나] 객체지향적 설계와 의존성 관리 본문

연관관계는 객체 참조가 있는 상태이다. A -> B로 영구적으로 갈 수 있는 경로가 있다고 보면 된다.
class A{
private B b;
}의존관계는 파라미터의 타입이 나오거나, 리턴 타입에 나오거나, 메서드 안에서 그 인스턴스를 생성하면 인스턴스이다.
일시적으로 관계 맺고 헤어지는 관계
class A{
public B method(B b){
return new B();
}
}1. 양방향 의존성을 피하라
- 성능 이슈
- sync를 맞출 때, 많은 버그를 만날 수 있다.
2. 다중성이 적은 방향을 선택하라
- 즉, One-To-Many보단 Many-To-One방향을 잡는 게 더 좋다
- 성능 이슈, 컬랙션의 관계들을 유지하기 위해 노력하는 게 너무 힘들다.
3. 의존성이 필요 없다면 제거하라
4. 패키지 사이의 의존성 사이클을 제거하라
- 설계의 중요성*: 변경을 고려해야 한다는 것
- 패키지 3개가 사이클 돈다는 것은 세 개의 패키지가 결국 하나의 패키지란 말이다.

[문제점]
1. 패키지 의존성 사이클
2. 객체 참조로 인한 결합도 상승

[해결]
* 의존성 역전 원리
class는 추상화에 의존하도록 -> 그렇다면 추상화는? 잘 변하지 않는 것,
1. 중간 객체를 이용해 의존성 사이클 끊기
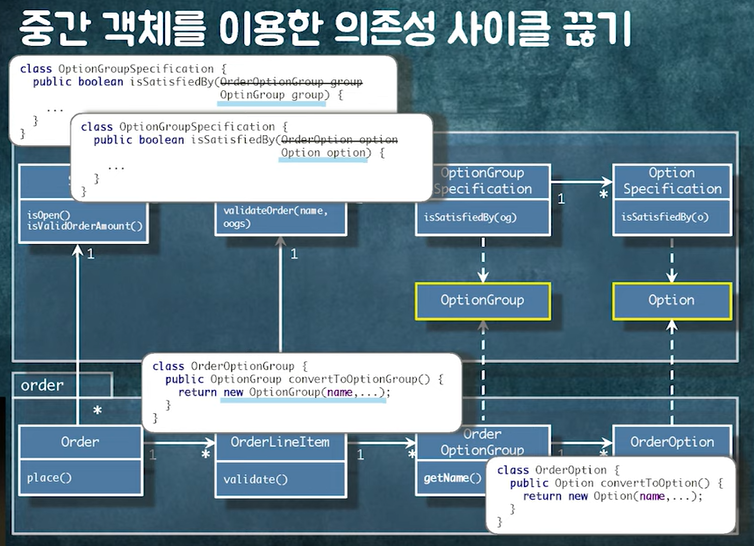
- Order -> shop 쪽으로 단방향으로 된다.
- OptionGroup, Option 추상화
2. 객체 참조로 인한 결합도 상승
- 성능 문제 - 어디까지 조회할 것인가?, 객체 그룹의 조회 경계가 모호
- 수정 시 도메인 규칙을 함께 적용할 경계 - 트랜잭션 경계는 어디까지인가?

트랜잭션으로 묶인 이러한 객체들이 트랜잭션이 몰리는 주기가 달라질 수 있다. 즉 한쪽에 몰려서 Lock이 걸리면 다른 부분까지 영향을 미친다. <- 트랜잭션 경합으로 인한 성능 저하

연관관계가 맺어져 있으면 위의 사진처럼 Order로 Shop을 탐색할 수 있다.
그렇다면 객체 참조를 통한 탐색은 강한 결합도를 가지므로 피하는 게 좋다.

그래서 약한 결합도를 갖는 탐색인 Repository를 통한 탐색을 해야 한다.
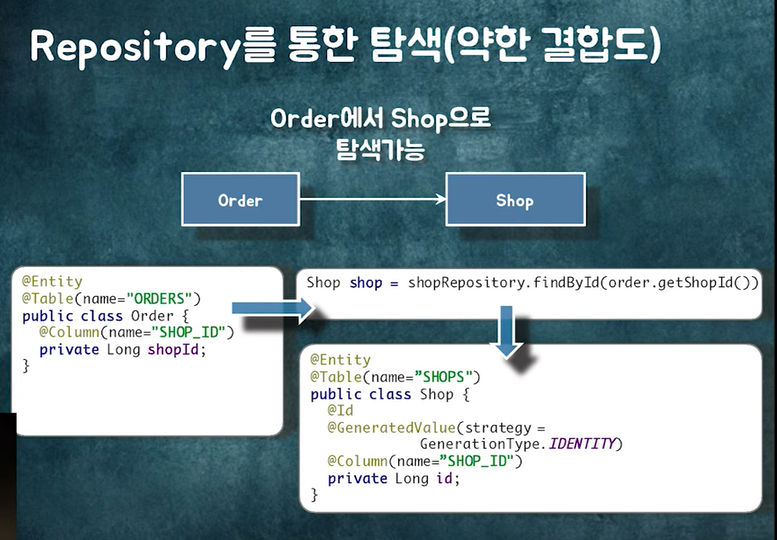
조회 로직들을 설계하다 보면 양방향 연관관계가 덕지덕지 붙게 되는데, 비즈니스 로직은 단방향으로 깔끔하게 만들 수 있다.
어떤 객체들을 묶고 어떤 객체들을 분리해야 할까?
- 간단한 규칙
1. 함께 생성되고 함께 삭제되는 객체들을 함께 묶어라
2. 도메인 제약사항을 공유하는 객체들을 함께 묶어라
3. 가능하면 분리하라 ex) Shop - (OrderLineItem, Order, OrderOptionGroup, OrderOption)
ex) 장바구니 - 장바구니 항목(하나로 묶을 줄 알았는데.. 장바구니 생성 시점과 장바구니에 항목을 넣는 시점의 라이프 사이클이 달라서 구별하는 게 좋다..!)
ex) 둘 사이에 constraint가 없다면 도메인 제약사항 공유 안 하므로 분리하면 된다.
- 동일한 가게의 상품만 넣어야 한다는 도메인 constraint가 공유하고 있으면 하나의 객체 그룹으로 넣으면 된다.
이것들은 비즈니스 룰에 의해 정해지지 정해진 답은 없다!
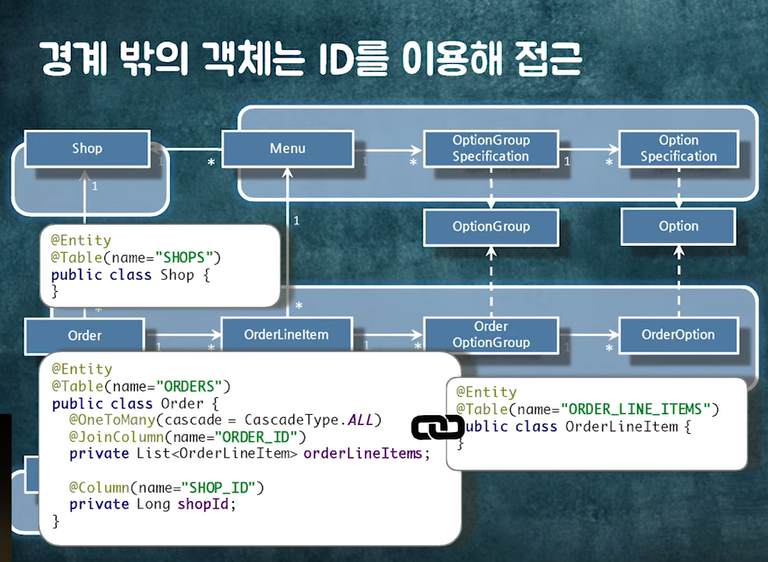
경계 안의 객체들은 연관관계로 묶는 게 좋다.(하자) 또한 함께 생성, 수정 등 변하므로 CASCADE를 주어도 된다.
그리고 경계 밖의 객체는 ID를 이용해 접근하면 된다!!😲😲
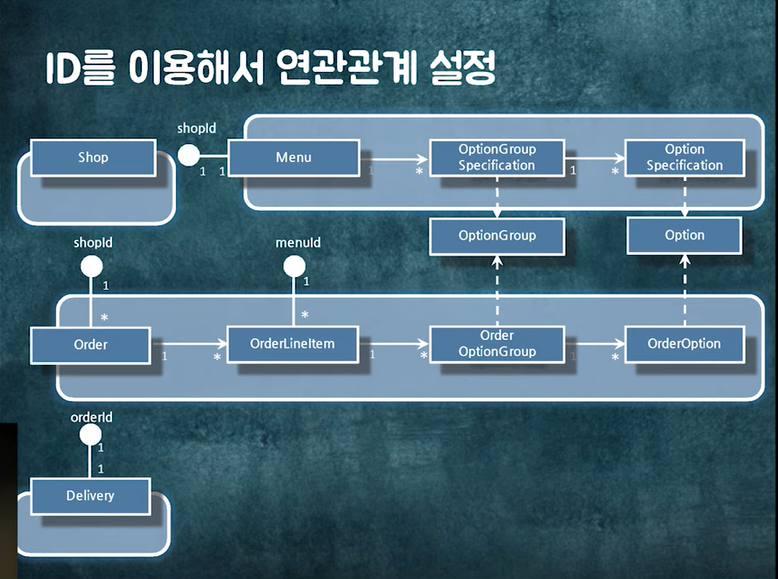
Order에서 Shop을 찾고 싶다면, Order에 shop_id로 ShopRepository를 이용해서 가져오면 된다.
위의 단위처럼 트랜잭션을 관리하면 되고 조회 경계도 위와 같이하면 된다.
같이 변경되는 애들이 뭉치면 응집도가 높다.
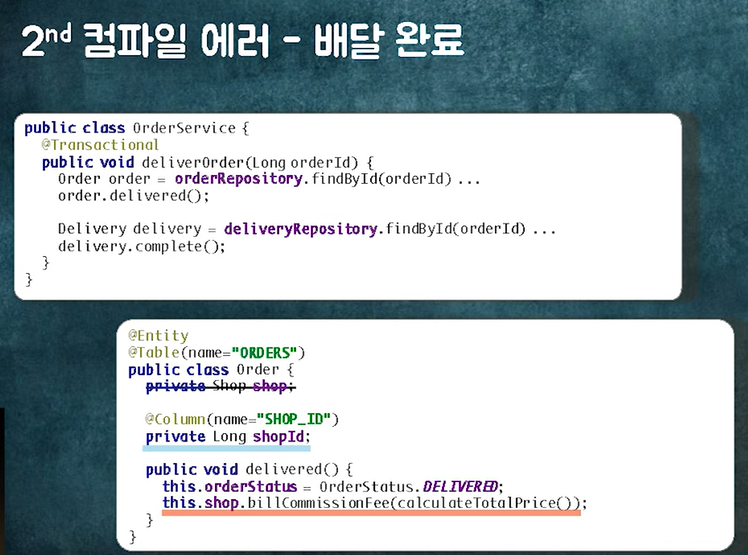
도메인 로직의 순차적 실행으로 인해 컴파일 에러가 생긴다.
Order이 변할 때, Delivery, Shop이 변경된다.
두 가지 해결법이 있는데,
1. 절차 지향적 방법 : 로직을 한 군데에 모아 객체 간의 결합도는 낮지만 로직 간의 결합도 명확
2. 도메인 이벤트 퍼블리싱: 로직 간의 순서를 느슨하게 만들기 위해서 ex) A->b->c
2.
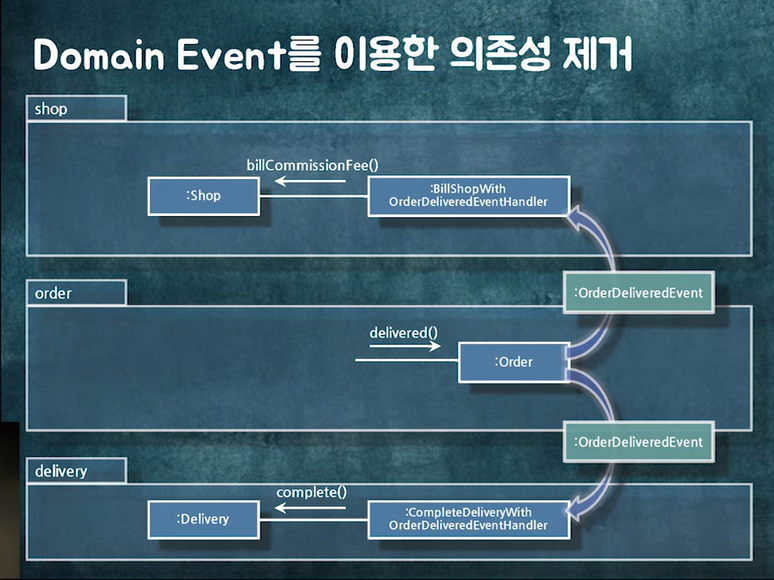

도메인 이벤트 발행 로직을 SpringData에서 제공하는 AbstractAggregateRoot를 상속해준다. 그러면 registerEvent()라는 메서드를 제공받고 거기에 원하는 event를 regist 하면 실제 db에 commit 할 때, 작동한다.


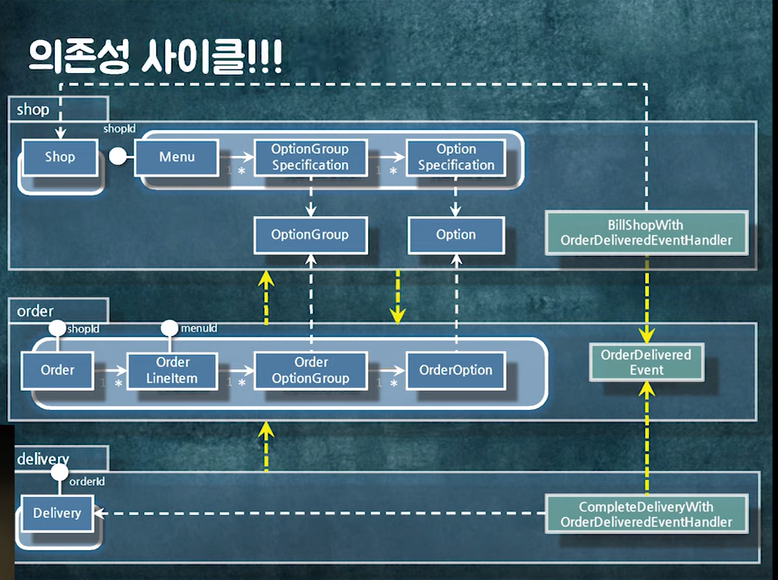
각각 넣고 의존성을 끊었으니 다시 의존성을 확인해보면... 사이클이 생긴다.
이번에는 패키지 의존성을 없애기 위해 새로운 패키지를 만들고 Event Handler가 의존하는 코드를 Shop에서 분리한다.
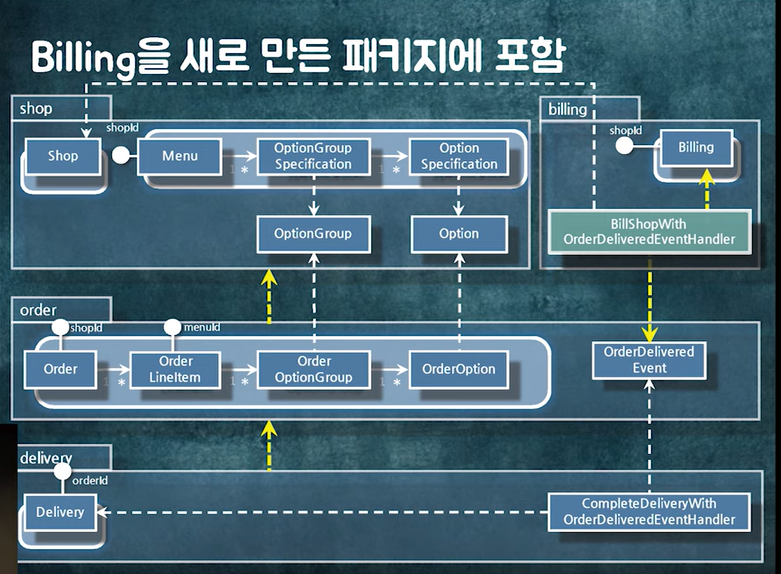
📚 패키지 의존성을 없애는 방법
1. 중간 객체 생성
2. 의존성 역전 (인터페이스나 추상 클래스)
3. 새로운 패키지 추가
결합도는 낮추고 응집도는 높이자!
2시간 가까이 세미나 중에서 나름 중요하다고 생각되는 부분만 정리했는데 그냥 다 중요한 것 같다.. 설계가 너무 어렵고 어떻게 해야 할지 감이 잘 안 잡혔는데 대충 큰 틀(?) 정돈 알 수 있게 되었다. 강의를 들으면서 이해가 안 가는 부분이 아직도 있지만 자주 들어보고 경험해봐야 완전히 이해를 할 수 있을 것 같다!😂
추가: Dto사용 범위
여러가지 방법이 있지만 실용적인 개발 아키텍처는 컨트롤러, 서비스, 리포지토리 계층이 모두 엔티티 계층에 의존하는 것입니다. 왜냐하면 엔티티라는 것이 우리의 핵심 비즈니스이기 때문에 대부분의 로직은 엔티티가 필요합니다.
추가로 DTO의 위치는 저는 해당 DTO를 생성하는 곳에 있어야 하는게 좋다 생각합니다.
예를 들어서 DTO를 리포지토리에서 생성하면 해당 리포지토리와 같은 패키지에 DTO가 있어야 패키지 의존관계가 안전하게 유지됩니다.
ex) DTO가 XXService에서 만들어진다면 XXService와 같은 패키지에 있는게 좋다 생각합니다.
그런데 보통 실수하는 것이 DTO를 서비스와 같은 계층에 두고, 리포지토리에서 해당 DTO를 사용하는 문제 입니다. 이렇게 되면 패키지 의존관계가 양방향이 됩니다. 서비스는 리포지토리가 필요하고, 리포지토리는 서비스가 제공하는 DTO가 필요한 문제이지요.
Refernce
- https://www.youtube.com/watch?v=dJ5C4qRqAgA&list=PLgXGHBqgT2TtGi82mCZWuhMu-nQy301ew&index=19
- https://www.inflearn.com/questions/139564
'백앤드 개발일지 > 웹, 백앤드' 카테고리의 다른 글
| ngrinder 성능테스트 [서버 부하 테스트] (4) | 2021.11.15 |
|---|---|
| NAVER CLOUD PlATFORM[SENS API] - 네이버 문자 인증 (5) | 2021.10.17 |
| 2주차 스터디 정리 (0) | 2021.06.26 |
| 1주차 스터디 정리 (0) | 2021.06.25 |
| Http-get, REST (0) | 2021.06.24 |


