
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 서블릿
- 우테코
- Spring Batch
- Paging
- yml
- AOP
- Docker
- Level2
- JPA
- 자바
- 미션
- 세션
- 우아한테크코스
- mock
- AWS
- CircuitBreaker
- 프리코스
- JUnit5
- 트랜잭션
- 스프링 부트
- 우아한세미나
- 의존성
- REDIS
- 백준
- 레벨2
- 스프링부트
- 코드리뷰
- MSA
- 프로그래머스
- HTTP
- Today
- Total
늘
rpc(GRPC) vs HTTP 본문
RPC
원격 프로시저 호출(Remote Procedure Call)은 네트워크의 세부 사항을 이해하지 않고도 한 프로그램이 네트워크의 다른 컴퓨터에 있는 프로그램에 서비스를 요청하는 데 사용할 수 있는 소프트웨어 통신 프로토콜이다.
RPC는 클라이언트 - 서버 모델이다. 요청하는 프로그램은 클라이언트이고, 서비스를 제공하는 프로그램은 서버이다.
로컬 프로시저 호출과 마찬가지로 RPC는 원격 프로시저의 결과가 반환될 때까지 요청 프로그램을 일시 중지해야 하는 동기 작업이다. 그러나 동일한 주소 공간을 공유하는 경량 프로세스 또는 스레드를 사용하면 여러 RPC를 동시에 수행할 수 있다.(+ grpc를 사용하면 비동기식으로 사용할 수 있다.)
API를 설명하는 데 사용되는 사양 언어인 IDL(인터페이스 정의 언어)은 원격 프로시저 호출 소프트웨어에서 일반적으로 사용된다. 이 경우 IDL은 링크의 양쪽 끝에 있는 서로 다른 운영 체제(OS)와 컴퓨터 언어를 사용하는 컴퓨터 사이에 중간다리 역할을 제공한다.
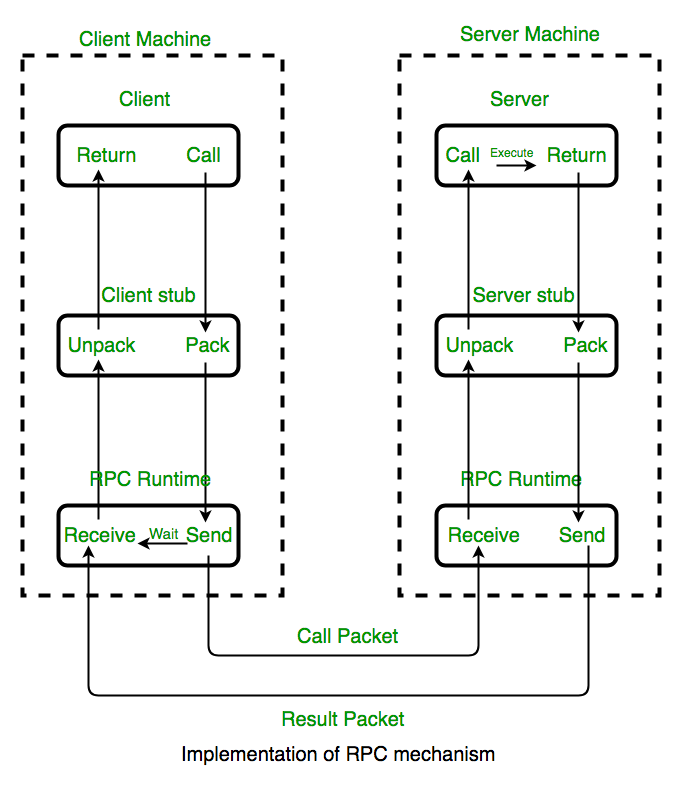
RPC stub
RPC 프레임워크를 사용하는 프로그램이 컴파일되면 원격 프로시저 코드를 나타내는 역할을 하는 컴파일된 코드에 stub이 포함된다. 프로그램이 실행되고 프로시저 호출이 실행되면 stub 코드는 요청을 수신하여 이를 로컬 컴퓨터의 클라이언트 런타임 프로그램에 전달한다. 클라이언트 stub이 처음 호출되면 nameserver에 접속하여 서버가 있는 전송 주소를 결정한다.
클라이언트 런타임 프로그램은 원격 컴퓨터와 서버 애플리케이션의 주소를 지정하는 방법을 알고 있으며 원격 프로시저를 요청하는 메시지를 네트워크를 통해 보낸다. 마찬가지로 서버에는 원격 프로시저 자체와 인터페이스하는 런타임 프로그램과 스텁이 포함되어 있다. 응답 요청 프로토콜은 동일한 방식으로 반환된다.
RPC 동작 원리
원격 프로시저가 호출되면 호출 환경이 일시 중단되고 프로시저 매개변수가 네트워크를 통해 프로시저가 실행될 환경으로 전송된 다음 해당 환경에서 프로시저가 실행된다.
프로시저가 완료되면 결과가 호출 환경으로 다시 전송되며, 여기서 일반 프로시저 호출에서 반환되는 것처럼 실행이 재개된다.
- 클라이언트는 클라이언트 stub을 호출한다.
- 클라이언트 스텁은 프로시저 매개변수를 메시지로 압축하고 시스템 호출을 통해 메시지를 보냅니다. 프로시저 매개변수를 패킹하는 것을 마샬링이라고 한다.
- 클라이언트의 로컬 OS는 클라이언트 시스템에서 원격 서버 시스템으로 메시지를 보낸다.
- 서버 OS는 들어오는 패킷을 서버 스텁에 전달한다.
- 서버 스텁은 메시지에서 언 마샬링(unmarshalling )이라고 하는 매개변수를 압축 해제한다.
- 서버 프로시저가 완료되면 서버 스텁으로 돌아가서 반환 값을 메시지로 마샬링한다. 그런 다음 서버 스텁은 메시지를 전송 계층으로 전달한다.
- 전송 계층은 결과 메시지를 클라이언트 전송 계층으로 다시 보내고, 클라이언트 전송 계층은 해당 메시지를 클라이언트 스텁으로 다시 전달한다.
- 클라이언트 스텁은 반환 매개변수를 정렬 해제하고 실행은 호출자에게 반환됩니다.
gRPC
rpc의 프레임워크인 gRPC는 구글이 최초로 개발한 오픈 소스 원격 프로시저 호출 시스템이다. 전송을 위해 HTTP/2를, 인터페이스 정의 언어로 프로토콜 버퍼를 사용하며 인증, 양방향 스트리밍 및 흐름 제어, 차단 및 비차단 바인딩, 취소 및 타임아웃 등의 기능을 제공한다. - 위키백과-
HTTP2, 프로토콜 버퍼가 핵심
프로토콜 버퍼
더 작고 빠르며 기본 언어 바인딩을 생성한다는 점을 제외하면 JSON과 같다. 데이터를 구조화하는 방법을 한 번 정의하면 특별히 생성된 소스 코드를 사용하여 다양한 데이터 스트림에서 다양한 언어를 사용하여 구조화된 데이터를 쉽게 쓰고 읽을 수 있다.
프로토콜 버퍼는 정의 언어( .proto파일로 생성됨), proto 컴파일러가 데이터와 인터페이스하기 위해 생성하는 코드이다. 파일에 기록되거나 네트워크를 통해 전송되는 데이터의 직렬화 형식의 조합이다.
프로토콜 버퍼는 언어 중립적이고 플랫폼 중립적이며 확장 가능한 방식으로 구조화된 레코드 형식의 데이터를 직렬화해야 하는 모든 상황에 이상적이다.
프로토콜 버퍼를 사용하면 다음과 같은 이점이 있다.
- 컴팩트한 데이터 저장
- 빠른 구문 분석
- 다양한 프로그래밍 언어에서의 가용성
- 자동 생성된 클래스를 통한 기능 최적화
주의사항
- 프로토콜 버퍼는 전체 메시지가 한 번에 메모리에 로드될 수 있고 개체 그래프보다 크지 않다고 가정하는 경향이 있다. 따라서 몇 메가바이트를 초과하는 데이터의 경우 다른 솔루션을 고려하자.
- 프로토콜 버퍼가 직렬화되면 동일한 데이터가 다양한 이진 직렬화를 가질 수 있다.
채널
gRPC 채널은 지정된 호스트 및 포트에서 gRPC 서버에 대한 연결을 제공한다. 클라이언트 스텁을 생성할 때 사용된다. 클라이언트는 메시지 압축을 켜거나 끄는 것과 같은 gRPC의 기본 동작을 수정하기 위해 채널 인수를 지정할 수 있다.
채널에는 connected및 idle등 의 상태가 있으며 virtual connection이 가능하다. 클라이언트가 채널을 만들면 내부적으로 http2 통신을 한다. gRPC가 채널 폐쇄를 처리하는 방법은 언어에 따라 다르며 채널에는 많은 rpc가 가능하다.
커넥션이 닫혀도 채널이 열려있으면 커넥션이 다시 맺어질 수 있다.
gRPC 클라이언트는 리졸버와 LB를 가지고 있다. 리졸버는 주기적으로 DNS를 리졸브하면서 앤드포인트를 갱신한다. 커넥션이 실패하면 LB는 직전에 사용했던 address list를 사용하여 재연결 시작한다. 커넥션 풀을 관리한다.

gRPC 요청과 응답
응답 메시지는 응답 헤더, length prefixed Message, Trailer 3가지이다.
Trailer 헤더는 http 스펙으로 grpc-status와 grpc-message를 포함

왜 gRPC에 특별한 로드밸런싱이 필요한가?(쿠버네티스 환경에서)
(쿠버네티스의 service는 L4, Ingress는 L7 로드밸런싱을 합니다.)
gRPC는 HTTP/2로 구축되었고, HTTP/2는 하나의 오래 지속되는 TCP 연결을 갖도록 설계되있기 때문에, 모든 요청은 다중화(multiplexed)(특정 시점에 다수의 요청이 하나의 연결에서만 동작하는 것을 의미)된다. 일반적으로, 그것은 연결 관리 오버헤드를 줄이는 장점이 있다.
그러나, 그것은 또한 연결 수준(L4)의 밸런싱(balancing)에는 유용하지 않다는 것을 의미한다. 일단 연결이 설정되면, 더 이상 밸런싱을 수행할 수 없기 때문이다. 모든 요청이 아래와 같이 단일 파드에 고정될 것이다.

HTTP/1.1에서는 발생하지 않는 이유
HTTP/2와 달리 HTTP/1.1은 요청을 다중화할 수 없다. TCP 연결 시점에 하나의 HTTP 요청만 활성화될 수 있다. 예를 들어 클라이언트가 'GET /foo'를 요청하고, 서버가 응답할 때까지 대기한다. 요청-응답 주기가 발생하면, 해당 연결에서 다른 요청을 실행할 수 없다.
gRPC with LB
gRPC 로드 밸런싱을 수행하려면, 연결 밸런싱에서 요청 밸런싱으로 전환해야 한다. 즉, 각각에 대한 HTTP/2 연결을 열어야 하고, 아래와 같이, 이러한 연결들로 요청의 밸런싱을 맞춘다.

네트워크 측면에서, L3/L4에서 결정을 내리기 보다는 L5/L7에서 결정을 내려야 한다. 즉, TCP 연결을 통해 전송된 프로토콜을 이해해야 한다.
방법
- 애플리케이션 코드는 대상에 대한 자체 로드 밸런싱 풀을 수동으로 유지 관리할 수 있고, gRPC 클라이언트에 로드 밸런싱 풀을 사용하도록 구성할 수 있다.
- 커스텀하므로 높은 제어력을 가지지만, 파드가 리스케줄링(reschedule)되면서 풀이 변경되는 쿠버네티스와 같은 환경에서는 매우 복잡
- 쿠버네티스에서 앱을 헤드리스(headless) 서비스로 배포
- 헤드리스 서비스만 사용하는 경우도 거의 없으므로 제약이 크다. (다음에 더 읽어봐야겠다.)
- 경량 프록시를 사용
- linkerd 나 istio처럼 서비스 메시를 사용한다.
- 각 파드에 작고, 초고속인 프록시를 추가하는 것을 의미하며, 이러한 프록시가 쿠버네티스 API를 와치(watch)하고 gRPC 로드 밸런싱을 자동으로 수행하는 것을 의미이다
REST API vs gRPC
- 통신 모델
- REST API를 사용할 때 클라이언트는 단일 REST API 요청을 서버에 전송한다.
- 하지만 gRPC는 여러 서버에 동시에 요청이 가능하다.
- 서버에서 직접적으로 호출 가능한 작업
- REST에는 URL로 정의된 서버 리소스에 대해 클라이언트에서 사용할 수 있는 제한된 HTTP 요청 동사 세트가 있다. 클라이언트는 리소스 자체를 직접적으로 호출한다. 이를 엔터티 지향 설계라고 하며 객체 지향 프로그래밍 방법과 잘 맞다.
- gRPC API에서 직접적으로 호출 가능한 서버 작업은 함수 또는 프로시저라고도 하는 서비스에 의해 정의된다. gRPC 클라이언트는 애플리케이션 내에서 함수를 직접적으로 호출하는 것처럼 간접적으로 호출한다. 이를 서비스 지향 설계라고 한다.
- 데이터 교환 형식
- REST API를 사용할 때는 소프트웨어 구성 요소 간에 전달되는 데이터 구조가 일반적으로 JSON 데이터 교환 형식으로 표현된다. XML 및 HTML과 같은 다른 데이터 형식을 전달하는 것도 가능하다. JSON은 읽기 쉽고 유연하지만 직렬화해야 하고 프로그래밍 언어로 번역해야 한다.
- 반대로 gRPC는 기본적으로 Protocol Buffer(Protobuf) 형식을 사용하지만 기본 JSON 지원한다. 서버는 프로토타입 사양 파일에서 Protocol Buffer 인터페이스 설명 언어(IDL)를 사용하여 데이터 구조를 정의한다. gRPC는 구조를 바이너리 형식으로 직렬화한 다음 지정된 프로그래밍 언어로 역직렬화한다. 이 메커니즘은 전송 중에 압축되지 않는 JSON을 사용하는 것보다 더 빠르다.
- 따라서 gRPC는 시간이 지나도 API가 변경될 가능성이 낮은, 여러 프로그래밍 언어로 구성된 마이크로서비스 아키텍처에도 적합하다. 또한 gRPC는 작동하려면 클라이언트 측과 서버 측 모두에 gRPC 소프트웨어가 필요하다.
Reference
What Is Remote Procedure Call (RPC)? Definition from SearchAppArchi...
당근마켓 gRPC 서비스 운영 노하우 | 당근마켓 SRE 밋업 1회
'백앤드 개발일지 > 웹, 백앤드' 카테고리의 다른 글
| Spring Batch 5 와 ??? (3) | 2024.01.08 |
|---|---|
| [오브젝트] 6장 메시지와 인터페이스 (2) | 2023.12.17 |
| 쿠버네티스 사알짝 맛보기 (0) | 2023.10.23 |
| 분산 시스템에서 데이터 처리(Queue, CDC, Outbox Pattern...) (0) | 2023.09.23 |
| [Tomcat]NIO Connector를 중심으로 (0) | 2023.03.18 |



