
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 코드리뷰
- 미션
- 의존성
- yml
- JUnit5
- HTTP
- Paging
- REDIS
- AWS
- 우아한테크코스
- JPA
- Spring Batch
- 프로그래머스
- 우아한세미나
- 자바
- AOP
- 트랜잭션
- mock
- Docker
- 스프링부트
- 세션
- 우테코
- Level2
- 스프링 부트
- MSA
- 백준
- 서블릿
- 레벨2
- CircuitBreaker
- 프리코스
- Today
- Total
늘
토큰과 세션(2) - 세션기반 인증 확장 방법 본문
서버가 확장되어 여러 개를 갖게 된다면 요청이 들어올 때마다 로드밸런싱을 통해 부하를 나눌 수 있다.
이때 세션을 사용하면 A라는 서버로 처음에 로그인을 해서 세션 ID가 만들어지고 로그인을 성공한다. 하지만 사용자가 다시 요청을 보낼 때 이번엔 로드밸런싱에 의해 B 서버로 갔다면 B서버에는 사용자의 세션ID가 없으므로 다시 로그인을 시도하라는 요청이 올 수 있다. 이러한 세션과 로드밸런싱의 문제를 해결하기 위해 sticky session이 있다.
sticky session
처음 로그인했을 때, 갔던 서버에서 세션 ID를 만들고 로그인이 성공하면 그 회원의 요청은 해당 서버로만 가도록 하는 것이다. 즉, 세션이 만들어진 서버로만 요청이 가는 것이다.
해당 방식은 cookie를 사용하는 방식으로 구현할 수 있다. 정합성에서는 좋지만 단점이 있다.
- 로드밸런싱을 제대로 활용하지 못한다. - 해당 사용자는 정해진 서버에게만 요청이 가므로 요청이 몰릴 수가 있다.
- 한 서버에 장애가 발생하면 해당 서버의 사용자들만 전부 로그아웃이 되어 가용성에 좋지 않다.
이러한 단점들을 해결하기 위해 Session Clustering이 있다.
Session clustering
여러 대의 컴퓨터들이 하나의 시스템처럼 동작하도록 만드는 것을 클러스터링이라고 한다.
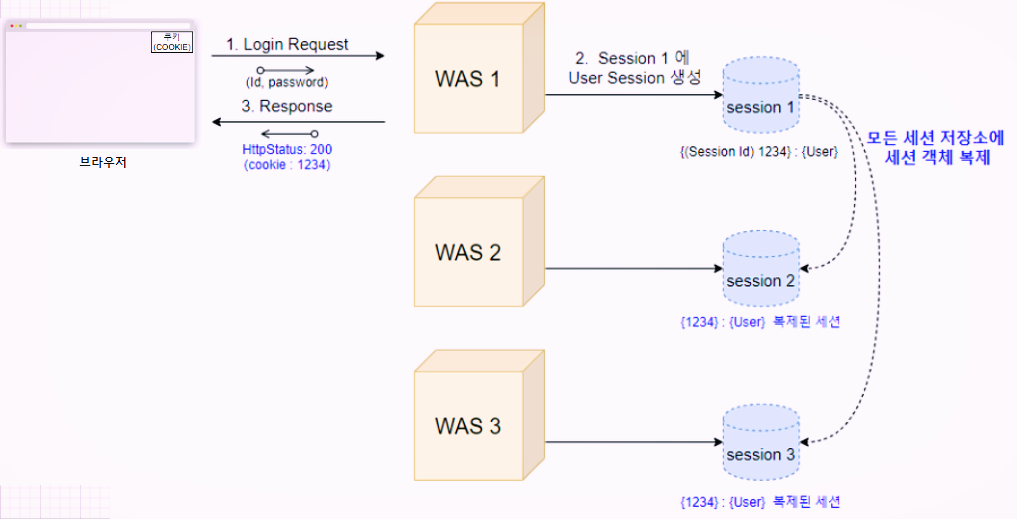
그림처럼 요청이 들어오면 디비에 세션을 저장한다. 그 후, 저장된 세션을 각 was의 디비에 똑같이 복제를 한다. 이렇게 하면 정합성도 해결되고, WAS1이 죽는다 하더라도 다른 WAS를 이용해도 되므로 사용자 입장에서는 로그아웃이 되는 불편함을 겪을 일이 없다. 하지만 이러한 세션 클러스터링의 단점은 보기에도 느끼겠지만 굉장히 수정이 빈번하다. 이는 휴먼 에러를 초래할 수 있다고 생각된다.
- 모든 was가 중복된 값을 가지므로 메모리를 차지하는 용량이 크다.
- 새로운 서버가 하나 뜰 때마다 기존의 was에서 새로운 서버의 IP/Port를 입력해서 클러스터링 해줘야 한다.
- 세션을 각 서버에 전달, 저장해야하기 때문에 서버 수에 비례하여 네트워크 트래픽이 증가하게 된다.
- 세션을 복제하여 전달 중에 전달되지 않는 곳으로 요청이 들어오면 로그인에 실패한다.
Session server분리
Redis를 이용한 Session clustreing을 이용하면 위의 상황을 피할 수 있다. redis뿐만 아니라 세션 스토리지를 따로 두어 관리할 수도 있는데 redis만의 장점이 있기 때문에 많이들 사용한다고 한다.
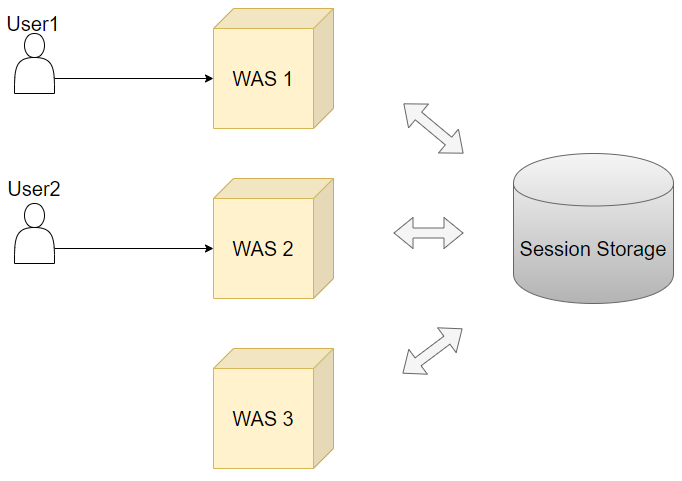
그림과 같이 별도의 서버를 구성한다.
- was가 추가된다 하더라도 복제할 세션이 추가되지 않으므로 메모리의 낭비가 줄어든다.
- 기존의 was는 건드리지 않아도 된다.
redis를 주로 사용하는 이유로는 아래와 같다.
- 일반적인 disk보다 redis는 in-memory db이기 때문에 비용이 큰 I/O에 대한 성능이 월등하다.
- disk에 저장하면 스케줄러등을 사용하여 주기적으로 만료된 토큰을 만료 처리하거나 제거해야 한다. 하지만, redis는 기본적으로 데이터의 유효기간(time to live)을 지정할 수 있다.
하지만 그림처럼 저장 공간이 한 곳에서 관리하므로 만약 스토리지가 날라간다면 모든 회원이 로그아웃 될 것이다. 또한 결국 모든 트래픽이 한 redis에서(replication을 적용한다고 하더라도) 받아내므로 보틀넥이 일어나지 않나라는 생각을 하게 된다.
다음번엔 토큰과 세션을 어떨 때에 사용해야 할지에 대해 정리를 해봐야겠다.
최종 정리: https://giron.tistory.com/137
Reference
'우아한테크코스 4기 > 프로젝트' 카테고리의 다른 글
| HTTP1.0 과 HTTP1.1 과 HTTP2 그리고 QUIC (2) | 2022.09.08 |
|---|---|
| 토큰과 세션(3) - 선택 (0) | 2022.08.29 |
| 토큰과 세션(1) - 토큰과 세션 그리고 쿠키에 대해서 (0) | 2022.08.23 |
| 소나큐브 적용기 (0) | 2022.08.15 |
| [테스트 자동화 1] service 테스트에서 롤백 목적으로 @Transactional 사용을 지양하자! 그런데 EntityManager를 활용해서 truncate를 시켜보자 (0) | 2022.07.29 |



