
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 우테코
- 스프링 부트
- 세션
- 레벨2
- Level2
- Spring Batch
- 스프링부트
- 자바
- 우아한세미나
- 백준
- Docker
- JUnit5
- 프로그래머스
- 의존성
- yml
- 미션
- JPA
- HTTP
- MSA
- 프리코스
- CircuitBreaker
- 우아한테크코스
- 트랜잭션
- Paging
- 서블릿
- mock
- AWS
- REDIS
- 코드리뷰
- AOP
- Today
- Total
늘
커서 기반 페이지네이션 적용기 본문
무한 스크롤 구현을 요구받아서 처리하려고 찾아본 결과 커서 기반 페이지네이션이라는 키워드가 있어서 찾아 공부해봤다.
1. 페이지네이션(Pagination) 이란?
- 전체 데이터에서 지정된 개수만 데이터를 전달하는 방법
- 필요한 데이터만 주고받으므로 네트워크의 오버헤드를 줄일 수 있다.
- 구현 방법에는 크게 두 가지가 있다.
- 오프셋 기반 페이지네이션 (Offset-based Pagination)
- 커서 기반 페이지네이션 (Cursor-based Pagination)
오프셋 기반 페이지네이션 - 페이징
- offset만큼 읽는데 이전의 읽었던 것을 다시 쭉 읽은 후 조회해서 데이터가 많아지면 성능상 안 좋다.
- 데이터 중복 문제: 2페이지 끝까지 읽었는데 앞에 최신 데이터가 들어오면 3페이지 읽을 때 중복이 발생할 수 있다.
- JPA에서는 Pageable을 이용해서 쉽게 구현할 수 있다.

커서 기반 페이지네이션 - 무한 스크롤
- offset을 사용하지 않고 Cursor를 기준으로 다음 n개의 데이터를 응답해주는 방식이다
- 따라서 Cursor가 unique 한 값이어야 한다.
- 정렬과 같은 기능을 사용할 때, pk값과 함께 사용해서 해결한다
- 데이터 중복이 발생하지 않고, offset과 다르게 이전의 데이터를 읽지 않고 바로 다음 cursor에 대한 정보를 주면 되므로 대량의 데이터를 다룰 때 성능상 좋다.
- 대신 where절에 여러 조건이 들어가면 성능이 offset보다 안 좋다고 한다.
- 여러 블로그에서 이야기해줬고 '페이스북이나 인스타그램도 그래서 정렬이 없구나'라고 생각했지만 유튜브에는 또 무한 스크롤로 정렬 기능이 있어서 더 알아봐야 할 것 같다.
단점
모든 기술엔 trade-off가 있듯이 커서기반페이지네이션의 단점이 있다.
1. where에 사용되는 기준 key가 중복이 가능할 경우이다. 이러면 정확한 값이 나오지 않는다.
2. 요구 사항에 1페이지에서 바로 5페이지로 건너 뛰는 요구사항이 있으면 불가능 하다.
중요한 점은 커서기반 페이지네이션은 인덱스를 통해서 원하는 페이지의 게시글에 바로 접근하는 기술이다. 아래의 예시처럼 무턱대고 커서기반을 적용한다고 속도가 빠른 것은 아니다!
테스트
Cursor기반 코드
return queryFactory
.selectFrom(article)
.where(
ltarticleId(cursorId),
categoryEquals(category)
)
.limit(pageSize)
.fetch();
}
private BooleanExpression ltarticleId(Long cursorId) {
return cursorId == null ? null : article.id.lt(cursorId);
}Offset기반 코드
return queryFactory
.selectFrom(article)
.where(
categoryEquals(category)
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}1만건 기준 처음 게시물을 조회할 때와 9800번째를 조회할 때도 큰 차이는 없었다.
그렇다면 10만건 기준으로 가보겠다.
9만 8천번째 게시물들을 조회 할 때이다.
Offset 기반

Cursor 기반

인덱스를 타지 않는 이상 Cursor기반 페이지네이션은 속도에서 의미가 없다.
인덱스를 통한 비교
더미데이터

offset 페이징

offset페이징을 하면 앞에서부터 쭉 보므로 18ms가 걸렸다.
No offset페이징
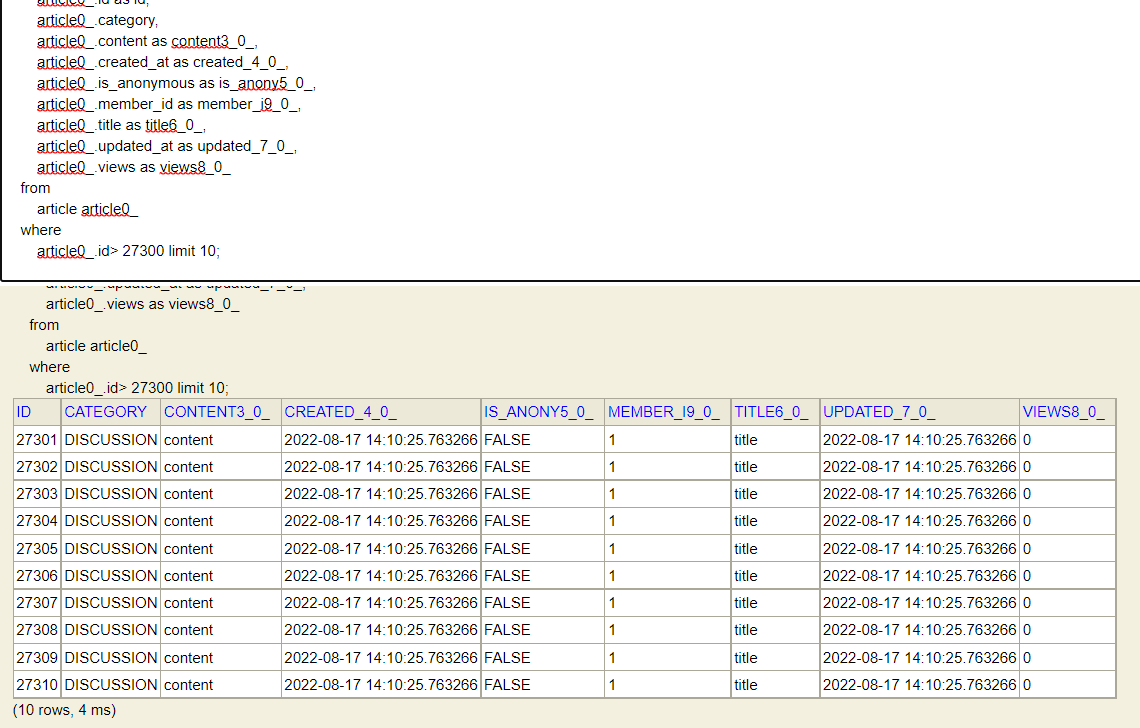
반면에 no Offset은 27300번부터 10개의 페이징을 했을 때, 4ms의 시간이 걸리는 것을 확인 할 수 있었다.
최신순 정렬
@Override
public List<Article> findAllByPage(Long cursorId, Integer cursorViews, String category, String sortType,
int pageSize) {
return queryFactory
.selectFrom(article)
.where(
ltArticleId(cursorId);
categoryEq(category))
.limit(pageSize + 1)
.orderBy(article.id.desc())
.fetch();
}
private BooleanExpression ltArticleId(Long cursorId) {
return cursorId == null ? null : article.id.lt(cursorId);
}
private BooleanExpression categoryEq(String category) {
return "all".equals(category) ? null : article.category.eq(Category.from(category));
}현재 최신순으로 구현되어있기 때문에 마지막으로 조회한 게시물의 id가 cursorId가 된다. 예를 들어 200~195번까지 조회를 했으면 다음 페이지를 조회할 때는 195가 cursorId가 된다.
따라서 article.id.lt(195)가 되고, 195보다 작은 다음 id들이 해당된다.
size+1만큼 가져온 이유는 hasNext라는 변수명으로 페이징 이후에 조회할 게시물이 있는지 확인하려고 size보다 한 개 더 가져온다.
그 후 fetch().size()가 size+1과 같으면 hasNext는 true가 되고, 아니면 hasNext는 false가 된다.
현재는 DTO의 의존성을 repository에서 갖기 싫어서 Entity조회로 했지만 추후에 성능이 안 좋아진다고 판단이 되면 DTO로 조회해서 한 번에 끌어오게 할 수도 있을 것이다.
정렬 기준에 따라 (조회수 정렬 or 최신순 정렬)
@Override
public List<Article> findAllByPage(Long cursorId, Integer cursorViews, String category,
String sortType, int pageSize) {
JPAQuery<Article> query = queryFactory
.selectFrom(article)
.where(
cursorIdAndCursorViews(cursorId, cursorViews, sortType),
categoryEq(category))
.limit(pageSize + 1);
if (sortType.equals("views")) {
return query.orderBy(article.views.desc(), article.id.desc()).fetch();
}
return query.orderBy(article.id.desc()).fetch();
}
private BooleanExpression cursorIdAndCursorViews(Long cursorId, Integer cursorViews, String sortType) {
if (sortType.equals("views")) {
if (cursorId == null || cursorViews == null) {
return null;
}
return article.views.eq(cursorViews)
.and(article.id.lt(cursorId))
.or(article.views.lt(cursorViews));
}
return ltArticleId(cursorId);
}
private BooleanExpression ltArticleId(Long cursorId) {
return cursorId == null ? null : article.id.lt(cursorId);
}
private BooleanExpression categoryEq(String category) {
return "all".equals(category) ? null : article.category.eq(Category.from(category));
}Slice를 사용한 hasNext
프로젝트를 진행하면서 프론트엔드에서 페이지를 조회할 때, 다음 elements가 있는지 hasNext같은 변수로 가르쳐달라고 했다. 해당 요구사항을 충족시키기 위해서 JPA의 Slice와 Pageable을 사용해서 구현을 할 수있다.
처음에는 Pageable을 받으면 무조건 offset을 사용한다고 생각해서 커서기반으로 페이지네이션을 하는 현재 상황에서 불필요하다고 생각했다. 하지만 Slice를 사용하려면 Pageable을 인자로 넣어줘야했었고 Slice를 사용하지 않고 구현을 했었다.
따라서 위의 코드처럼 List에서 limit(pageSize + 1)만큼 조회하고 service layer에서 분기처리를 통해 hasNext를 입력해주었다. 위처럼 작성하면 repository에서 pageSize만큼 데이터를 추출해주는 역할이 service layer로 넘어갔다는 것을 확인할수 있고, 이는 데이터의 응집도가 떨어진다고 생각했다.
따라서 hasNext를 repository내에서 판단하기위해 Pageable을 인자로 받고 Slice를 통해서 구현하였다.
(사실 repository에서 바로 Dto로 반환을 한다면 Pageable이나 Slice를 의존하지 않고도 repository내에서 처리할 수 있다. 또한 영속성컨텍스트에 엔티티를 적재하지 않으므로 불필요한 영속성컨텍스트 차지를 막고 엔티티의 사용하지 않는 컬럼까지 조회할 일이 없다.) 하지만 현재는 Article의 대부분이 Dto에도 들어가므로 엔티티를 조회하는 것이 Dto의 의존을 repository까지 들어오는 것 보단 이득이라고 생각이 되었다. 하지만 요구사항으로 like의 수도 반환하므로 현재처럼 하면 article조회 후, 다시 like를 조회하는 쿼리가 나가므로 추후 Dto를 반환하도록 리펙토링할 예정이다!
public Slice<Article> findAllByLikes(Long cursorId, Long cursorLikes, String category, Pageable pageable) {
List<Article> fetch = queryFactory
.select(article)
.from(like)
.rightJoin(like.article, article)
.where(categoryEquals(category))
.groupBy(article)
.having(cursorIdAndLikes(cursorId, cursorLikes))
.limit(pageable.getPageSize() + 1)
.orderBy(like.count().desc(), article.id.desc())
.fetch();
boolean hasNext = false;
if (fetch.size() == pageable.getPageSize() + 1) {
fetch.remove(pageable.getPageSize());
hasNext = true;
}
return new SliceImpl<>(fetch, pageable, hasNext);
}
private BooleanExpression cursorIdAndLikes(Long cursorId, Integer likes) {
if (cursorId == null || likes == null) {
return null;
}
return like.count().eq((long) likes)
.and(article.id.lt(cursorId))
.or(like.count().lt(likes));
}
private BooleanExpression categoryEq(String category) {
return "all".equals(category) ? null : article.category.eq(Category.from(category));
}Reference
https://jojoldu.tistory.com/528
'우아한테크코스 4기 > 프로젝트' 카테고리의 다른 글
| 토큰과 세션(1) - 토큰과 세션 그리고 쿠키에 대해서 (0) | 2022.08.23 |
|---|---|
| 소나큐브 적용기 (0) | 2022.08.15 |
| [테스트 자동화 1] service 테스트에서 롤백 목적으로 @Transactional 사용을 지양하자! 그런데 EntityManager를 활용해서 truncate를 시켜보자 (0) | 2022.07.29 |
| HTTPS 적용하기 (0) | 2022.07.28 |
| [JPA] cascade = CascadeType.REMOVE와 @OnDelete(action = OnDeleteAction.CASCADE)의 차이 (0) | 2022.07.24 |



